Understanding Concurrency, Parallelism and JS
Written at 2024-09-08 - Updated at 2024-09-18Up until now, I was not aware that concurrency and parallelism were actually different things since they are often used interchangeably by some. I just learned that this is not the case while reading Chapter 9 of the book “Clojure for the Brave and True.”
This made me want to learn more about concepts related to concurrency and parallelism, especially concerning the programming language I know best: JavaScript. So this essay is basically a collection of notes I made during this learning process.
Sequential, Concurrent and Parallel
When executing tasks in our lives, we execute them sequentially, concurrently, or parallel. And this applies to computing as well.
Sequential execution is basically when tasks are done one after another without any overlap. For instance, if someone first looks at their phone, finishes their job with it, and only after that switches to another task, for example, to eat their soup, they are working sequentially. The problem with this approach is sometimes your tasks are getting blocked, like for example when you ask a thing to your friend from your phone, if you don’t switch to other tasks until your friend answers, you will basically lose time. So different forms of multitasking can be of help from time to time to save time. Concurrency and parallelism are ways to achieve multitasking. But there are subtle, yet important differences between the two.
Concurrency is like handling numerous tasks by alternating between subtasks (aka interleaving), while parallelism is like performing multiple tasks simultaneously. For example, if someone looks at their phone, puts it down to take a spoonful of soup, and then returns to their phone after setting down the spoon, they are working concurrently. In contrast, if a person is texting with one hand while eating with the other at the same time, they are working in parallel. In both cases, they are multitasking, but there is a subtle difference in how they multitask.
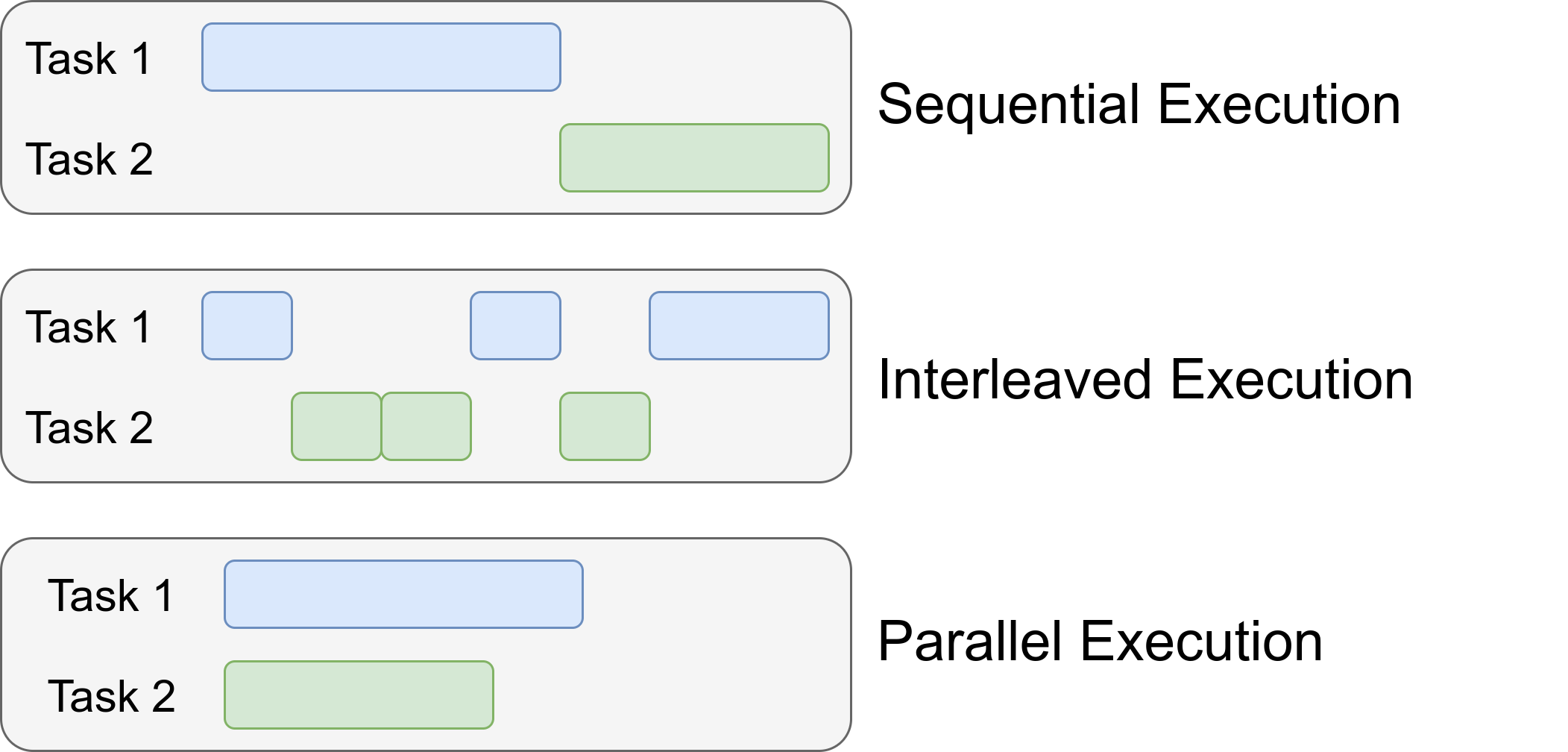 (Image taken from Synchronous vs Asynchronous vs Concurrent vs Parallel)
(Image taken from Synchronous vs Asynchronous vs Concurrent vs Parallel)Threads
In the analogy above, I referred to eating soup and using the phone as different tasks and each task consists of subtasks (for example eating soup, you need to hold the spoon, then put it into your soup, then put that into your mouth, and so on…).
Likewise, in the context of programming, the subtasks can be thought of as individual segments of a larger set of instructions in a process. The conventional way to operate on different subtasks simultaniously is to create different kernel threads. Which are, kind of like separate workers each handling their specific tasks while being able to work on the same set of instructions as well as resources.
Whether your threads run in parallel or concurrently actually depends on your hardware. If your CPU has more cores than the number of threads running simultaneously, each thread can be assigned to a different core, allowing them to operate in parallel. However, if your CPU has fewer cores than the number of threads, the operating system will start interleaving between the threads.
When it comes to kernel threads, the developer’s experience remains the same, whether the tasks are actually handled concurrently or parallelly does not make much of a difference. The developer uses threads to improve performance and avoid blocking. However, it’s the operating system that makes the final decision on how to handle these threads depending on the resources available. As long as the developer uses threads, whether they run concurrently or in parallel, it doesn’t matter; in both cases, the order in which instructions from different threads are executed is kind of unpredictable. Therefore, the developer should be cautious of potential issues (like race conditions, deadlocks, livelocks, etc) that can occur from two different threads operating on the same data anyway!
Spawning Processes, I/O Notifications
There are also other ways to achieve concurrency/parallelism other than using threads, for example although not as efficient as threads, spawning multiple processes is another way to go. Since the CPU runs different processes both parallely and concurrently, you can multitask using many processes. The disadvantages here are that each process comes with its own memory space allocated and they don’t share their memory space by default like threads. So, if you need different processes to operate in the same state, you might need some sort of an IPC mechanism like shared memory segments, pipes, message queues, or even databases.
Kernels also implement their own way of I/O event notification mechanisms, which again, can also be helpfull when building programs that you don’t want to get blocked while doing certain tasks.
I don’t want to delve into much details, since I don’t know much about it, but the key idea is, kernel threads are not the only OS specific way that you can achieve concurrency.
NodeJS, an Example for User-space Concurrency
Programming languages often provide their own concurrency mechanisms to simplify the complexities associated with using the Operating System’s API (system calls). This means that the compiler or interpreter can translate your high-level code into low-level system calls that the operating system understand so that you don’t have to think much.
Node.js is a great example of this concept. Although your JavaScript program runs in a single-threaded environment with a sequential execution flow, blocking tasks such as IO operations are delegated to the Node.js Worker Threads. So NodeJS uses threads behind the scenes to manage those blocking tasks, without revealing the complexities of managing them to the developer.
Here’s how it works: Blocking operations, such as writing to a file or reading from a file, or sending a network request are typically handled using the built-in functions provided by Node.js. You usually pass callback functions as parameters when calling these functions, so that Node.js Worker Threads can execute the callback functions that you provided when they complete their tasks.
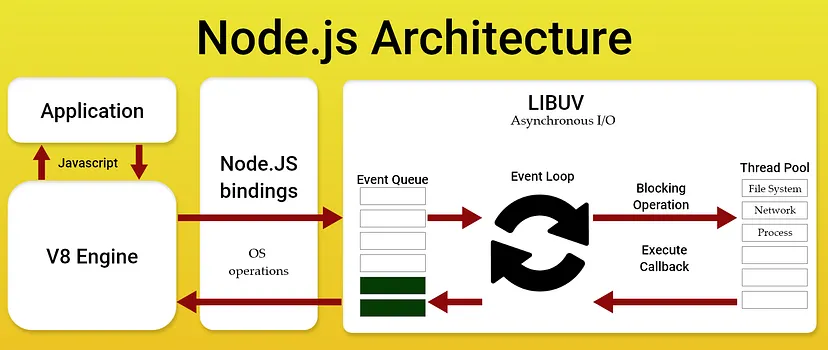 (Image taken from NodeJS Architecture)
(Image taken from NodeJS Architecture)Having a bit of more idea how NodeJS concurrency works under the hood, we can now start practicing this theory by examining certain cases/situations.
Consider the following code (thanks to my friend Onur for coming up with the example);
setTimeout(() => {
while (true) {
console.log("a");
}
}, 1000);
setTimeout(() => {
while (true) {
console.log("b");
}
}, 1000);
Here, if you run this program, the only thing you will encounter on your screen will be “a"s. This is because the NodeJS interpreter continue executing the current callback as long as there are instructions still available.
As soon as all instructions in the main code are executed, the NodeJS runtime
environment then starts calling the callback functions. You can also think of
the main code you write as being called by default as a callback. In the
example above, the first setTimeout is executed with the callback function
provided, and the second setTimeout is executed with the callback function
provided. After 1 second passes, it starts spamming “a"s. You never see “b"s
because, once the first callback is called, it dominates the main thread with
its ugly while loop, forever! So, the second callback is never called.
This has a few important effects. First, it reduces the chance of issues like
race conditions, though they can still happen, especially compared to
multi-threaded languages like C. Why? In C-like languages, the CPU interleaves
threads at the instruction level, while here, it mostly happens at the callback
level. As long as you avoid having complicated logic that relies on async
functions with nested callbacks, it is certain that the flow of execution
remains uninterrupted, basically sequential.
If the programming logic contains many asynchronous callback-based functions
(like fs.readFile(), setTimeout(), setImmediate(), or even
Promise.then()), the race conditions can easily start to occur.
This also applies to the usage of await because you can think of await
statements as shorthand for wrapping the remaining code in the current scope
into a callback function that runs once the awaited Promise is resolved.
Consider the test and test2 functions provided below:
const
{scheduler} = require('node:timers/promises'),
test = async () => {
let x = 0
const foo = async () => {
let y = x
await scheduler.wait(100)
x = y + 1
}
await Promise.all([foo(), foo(), foo()])
console.log(x) // Returns 1, not 3
},
test2 = async () => {
let x = 0
const foo = async () => {
await scheduler.wait(100)
let y = x
x = y + 1
}
await Promise.all([foo(), foo(), foo()])
console.log(x) // Returns 3
},
main = () => {
test()
test2()
}
main()
The reason test() logs 1 is that when the foos functions are called, as soon
as they encounter await scheduler.wait(100), they essentially finish. Because
under the hood, using await scheduler.wait(100) evaluates something like the
following:
scheduler.wait(100).then(() => {
x = y + 1
})
So, the first foo function finishes its job, it is now upto the callback
function to continue the business, but since it will only be called 100ms
after, the NodeJS interpreter does not stay idle but instead continues
executing the second and third foo functions by order. They also set y
variable to the value of x before the callback from the first foo is
triggered, and call scheduler.wait with the callback function. As a result,
when the callbacks are eventually executed, they all update x using the
previous value of x, so we get 1, instead of 3.
Why we get 3 logged out when running test2()? Because the place where await
is being run is different and it evaluates to something like
scheduler.wait(100).then(() => {
let y = x
x = y + 1
})
As soon as this callback function is called, nothing can interleave between
let y = x
x = y + 1
So, no race condition can occur.
To Conclude
The main idea here is that there is not just one way to achieve “concurrency”, and the way you achieve it can also affect many things, like how performant your programs will be or even what kind of problems you can encounter, or what things to watch out for and so on.
Just try to be mindful when working on programs that are supposed to work concurrently/parallelly. Things can go wrong pretty fast.
Addendum
2024-09-18: This essay received a lot of attention that I did not anticipate. It got 99 upvotes on HackerNews and appeared on the front page for a while. A few days later, my friend Carlo informed me that my essay was featured in the 323rd issue of the Bytes newsletter, a JavaScript newsletter with over 200,000 subscribers.
I’ve also received a few messages expressing appreciation for the essay and even got the first pull request to my blog’s GitHub repository. Thanks to everyone who took the time to read and provide feedback.
In the HackerNews discussion, @duped and @donatj recommended Concurrency is not Parallelism by Rob Pike. It is a very good talk, so I wanted to mention it here as well for anyone else further interested in the topic.